Welcome to  by Kuriko IWAI.
by Kuriko IWAI.
LLM fine-tuning, causal ML, agentic RAG, and production MLOps.
Kernel Labs by Kuriko IWAI publishes practitioner-grade research—ordered series on causal inference and model fine-tuning, deep dives across LLM engineering and MLOps, plus hands-on courses and interactive labs for ML engineers shipping production systems.
Shipping AI Systems?
I help teams design and deploy scalable ML / RAG / LLM pipelines and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground

Hosted by Kuriko IWAI
Recommended Reads
SERIES
Causal Machine Learning
Structural causal models, backdoor adjustment, and IPS for production decision systems.
Model Fine-Tuning
End-to-end LLM adaptation: PEFT, QLoRA, preference alignment, and multi-adapter serving.
- P01The Definitive Guide to LLM Fine-Tuning: Objectivee, Mechanisms, and Hardware
- P02Deconstructing LoRA: The Math and Mechanics of Low-Rank Adaptation
- P03A Technical Guide to QLoRA and Memory-Efficient Fine-Tuning
- P04Aligning LLMs with Direct Preference Optimization (DPO)
- P05Building LoRA Multi-Adapter Inference on AWS SageMaker
BY GOAL
What's New
Fixing Selection Bias in Enterprise Data with Inverse Propensity Scoring (IPS)
[Series] Causal Machine Learning - 2. De-Biasing Historical Data Logs (without Expensive A/B Tests)
Standard machine learning models fail when observational data is poisoned by selection bias—mistaking baseline confounding for true treatment impact.
Inverse Propensity Scoring (IPS) provides an offline mathematical simulator that transforms biased operational logs into synthetic Randomized Controlled Trials (RCTs).
This guide breaks down the underlying propensity mathematics, positivity constraints, and production Python code to calculate unconfounded Average Treatment Effects (ATE).
The absolute cleanest way to solve our project routing dilemma is a Randomized Controlled Trial (RCT).
An RCT is a scientific experiment where baseline biases are eliminated by design using a perfectly random allocation mechanism.
◼ Core Mechanism
Below diagram illustrates its mechanism:

Figure B. Workflow diagram of a Randomized Control Trial (RCT) showing candidate pool randomization into balanced treatment and control groups (Created by Kuriko IWAI).
In an RCT, a pool of subjects is split into a treatment group (A_0 = 1) and a control group (A_0 = 0), following:
Control Group: A baseline group that receives no intervention (e.g., keeping developers on standard maintenance).
Randomization: Allocation is completely randomized. All potential baseline biases—whether they stem from a candidate's university pedigree, years of experience, or technical stack—are distributed evenly across both groups.
Blinding: To further mitigate psychological or observer biases, subjects (single-blind) or both subjects and researchers (double-blind) are kept unaware of group assignments.
By balancing these baseline traits perfectly, RCTs provide the surest means of achieving two critical benchmarks of research quality:
Internal Validity: Ensuring that the relationships found within the study data reflect true, unconfounded causal relationships in the target population.
External Validity: Ensuring that the results calculated by the model can be confidently applied to similar populations in different real-world settings.
◼ Applied to the Use Case: The Live Hiring RCT
If we ran a pristine RCT in our engineering org, we would take a fresh pool of 1,000 incoming developers.
Regardless of whether they went to an Ivy League university or a self-paced coding bootcamp, we would flip a coin:
Heads (A_0 = 1) → Sent directly to a Tier-1 Cloud Architecture project.
Tails (A_0 = 0) → Sent directly to standard maintenance.
Because both groups are structurally identical at day zero, any variance in our final 1-year retention outcome (Y) could be confidently attributed to the project assignment (A_0) alone.
Mapping Analytical Frameworks
While the live hiring RCT yields perfectly clean data, running it in a production environment hits an immediate operational wall.
◼ Why Live Hiring Experiments Fail Operationally
There are two main reasons that the experiment fails in production:
Severe operational risk and
Ethical constraints.
▫ 1. Severe Operational Risk and Costs
Forcing a randomized assignment policy is hazardous.
If we randomly assign an under-qualified team to a critical tier-1 infrastructure project just to gather unconfounded data, we'd risk catastrophic downtime and lost revenues.
▫ 2. Ethical Constraints
It can be highly disruptive to intentionally strip career-advancing, beneficial treatments like premier projects away from a control group simply to satisfy an algorithmic requirement.
◼ Alternative Analytical Studies
Because of these operational frictions, we must pivot to alternative study designs.
The below diagram shows the breakdown of analytical study designs:

Figure C. Taxonomy chart of analytical study designs categorizing experimental variants and observational frameworks like cohort, case-control, and cross-sectional studies.
▫ A. Experimental Variants
Non-Randomized Controlled Trials: We actively manipulate the assignment policy, but rely on non-random criteria (like team tenure or hiring dates) to form groups.
Use Case Example: We roll out an automated Tier-1 project routing pilot exclusively to our Tokyo office, while keeping our New York office on legacy manager routing.
The Causal Flaw: Without a random coin flip, the baseline traits ($X$) of the Tokyo engineering culture differ systemically from New York, leaving the door open for hidden regional confounders.
▫ B. Observational Frameworks
When we cannot manipulate project assignments at all, groups form naturally in historical operational logs.
Cohort Studies:
Isolates a group of developers right at their hire date, record their initial baseline context, and actively follow them forward over a 12-month period.
Use Case Example: Tracking developers as they naturally land Tier-1 projects or standard maintenance based on legacy human manager preferences.
Case-Control Studies:
Instead of waiting 12 months, identifies two terminal groups: the “Cases” (developers who left the company within 1 year) and the “Controls” (developers who stayed). We then analyze their past logs to check what project exposures and baseline traits drove the split.
Use Case Example: This is a massive time-saver for studying rare infrastructure failures or extreme corporate attrition, though we must heavily adjust for survivorship bias.
Cross-Sectional Studies (Snapshots):
Measures exposure and outcomes at the exact same time.
Use Case Example: Pulling a data dump of our entire global directory today to see which developers are currently on Tier-1 projects and matching that to their current Q3 happiness score. It provides a quick operational snapshot but cannot establish a clear chronological sequence of events.
▫ Comparing RCTs and Observational Alternatives
To see exactly how these choices impact our causal pipeline, let us map our project routing challenge across these methodologies:
Study Framework | Practical Execution in Our Use Case | Structural Advantage | Causal Vulnerability |
RCT | Assigning bootcamp grads and Ivy grads to Tier-1 projects based purely on a 50/50 coin flip. | No Unobserved Confounding: Balances both measured and unmeasured traits. Simple ATE calculation. | Extreme Business Friction: High financial risk, threat of client churn, and severe ethical barriers. |
Prospective Cohort Study | Tracking new hires for a year as human managers hand-pick who gets Tier-1 assignments. | Zero Operational Risk: Passively mines existing operational data without disrupting current manager workflows. | Severe Selection Bias: Elite profiles are heavily over-represented in the Tier-1 treatment branch. |
Retrospective Case-Control | Extracting data from developers who already quit (Y=0) vs. those who stayed (Y=1) to see what projects they worked on. | Speed and Efficiency: Yields rapid risk factors and odds ratios without waiting 12 months for prospective tracking. | Survivorship Bias: Sampling based on the final symptom (Y) rather than the initial baseline action (A_0). |
Table 1. Methodological Trade-offs: Randomized Experiments vs. Observational Cohorts
Unmeasured Confounder - The Universal Blind Spot
If an unmeasured confounder exists across either observational design, any observational analysis will misattribute its effect to the intervention.
For example, when a developer has unrecorded motivation that simultaneously makes them work harder and get picked for better projects, the true impact of the intervention cannot be measured.
This is precisely where Inverse Propensity Scoring (IPS) steps in to act as an offline algorithmic simulator.
Shipping AI Systems?
I help teams design and deploy scalable ML / RAG / LLM pipelines and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground
What is IPS - Synthetic Re-Weighting Explained
Because running RCT in our use case is operationally too risky, we must debias our historical data logs synthetically.
Inverse Propensity Scoring (IPS) is a causal inference framework designed to estimate the true causal effect of an action when running a live RCT is impractical.
The below diagram illustrates its core concept:

Figure D. Distribution graph demonstrating how Inverse Propensity Scoring (IPS) re-weights skewed observational data into a balanced synthetic sample (Created by Kuriko IWAI)
Figure D shows that IPS can synthetically adjust the balances by re-weighting the original population with selection biases.
In our use case, when an Ivy League graduate (red circles, Figure D) had a 95% chance of being selected for a Tier-1 project based on their pedigree, their data point is down-weighted (IPW = 1.05 < 20).
Conversely, if an equally capable engineer from a non-traditional background (orange circle, Figure D) was selected for a Tier-1 project against all historical odds (a 5% probability in reality), their data point is up-weighted by a factor of 20 (IPW = 20).
This synthetic adjustment balances the distribution of baseline confounder X to look statistically identical across both groups.
◼ The Exchangeability of IPS
The exchangeability of IPS indicates its ability to transform a biased historical log into a clean, pseudo population where treatment and control groups can be fairly compared without risking live revenues.
This is critical to causal inference.
Causal inference attempts to answer prescriptive questions such as:
"What will happen to our retention rate if we change our active policy and assign this specific cohort to a Tier-1 project?",
But in reality, causal inference faces counterfactuals where it cannot observe what would happen when Engineer A were assigned to the control group (A_0 = 0), and vice versa.
So, without IPS, causal inference collapses because confounding (high-performing profile) simultaneously causes a higher likelihood of being assigned to the treatment group (A_0 = 1), and can naturally exhibit higher retention (Y).
1 [Confounder: Engineer with Pedigree (X)]
2 / \
3 / \
4 v v
5[Project Assignment (A0)] ----------> [1-Year Retention (Y)]
6Figure E. Causal loop diagram showing baseline confounder X directly influencing both the treatment action A_0 and the retention outcome Y, resulting in entangled correlation and causation (Created by Kuriko IWAI)
IPS can mathematically strip away this dilemma.
Mathematical Proof: How IPS Debias Data and Secure Statistical Independence
To understand how IPS achieves synthetic randomization, let us look at the underlying mathematical framework.
◼ Core Variables
IPS has three key variables:
X: Baseline confounder. A vector of observed baseline confounders. In the hiring context, X can be a jobseeker's professional background.
A_0 ∈ {0, 1}: An intervention. The binary treatment indicator represents the primary initial action. For instance, A_0 = 1 if assigned to a complex Tier-1 project, A_0 = 0 if assigned to standard maintenance.
Y: The target outcome. For instance, retention status or promotion after 1 year. Y(1), Y(0 indicate the potential outcomes (counterfactuals) if the jobseeker were un/treated by the intervention A_0 (e.g., assigned a complex project), respectively.
◼ Propensity Score
The propensity score e(X) is the conditional probability of receiving the treatment given the baseline confounder X:
where A_0 = 1 represents that an individual (jobseeker) is assigned to an intervention A_0.
In an enterprise ML pipeline, this score is typically estimated using a calibrated binary classifier such as Logistic Regression or LightGBM trained on historical logs to predict A_0 from X.
◼ Estimating IPS
To isolate the true structural impact of our action, the Average Treatment Effect (ATE) can measure the average total causal impact of the policy change across the entire population.
Mathematically, ATE is denoted:
Here, E[Y(1)] is the expected value of the outcome if every single individual in the population had been forced into the treatment group (A_0 = 1).
In the hiring context, this represents a situation where all jobseekers (employees) are assigned to the competitive project A_0 = 1 for instance.
On the other hand, E[Y(0)] is the expected value of the outcome when A_0 = 0, meaning all jobseekers are assigned to a simple, baseline project.
Because we can never simultaneously observe both Y(1) and Y(0) for a single individual, the IPS estimator allows us to calculate these unobserved counterfactual expectations using only observed data by applying Horvitz-Thompson inverse weights:
Where:
A_0 ∈ {0, 1} is the observed treatment assignment for a given individual.
Y is the actual observed outcome.
e(X) is the estimated propensity score for that individual.
A_0⋅Y / e(X) zero-out anyone who did not receive the treatment (A_0 = 0) and dynamically amplifies the outcomes of individuals who received the treatment despite a low historical probability.
◼ Computing Causal Weight
To operationalize this, the IPS pipeline computes an individual causal weight (w_i) for every single data point in our cohort:
For example:
For Engineer A: Ivy League Grad, 5 YOE
Because managers actively favor this profile for top tasks, their estimated propensity score is highly skewed: e(X_A) = 0.95.
They were assigned a Tier-1 project (A_A = 1).
For Engineer B: Non-traditional background, 1 YOE
Because managers usually bypass this profile, their propensity score is low: e(X_B) = 0.05.
Due to an emergency staff shortage, they were assigned a Tier-1 project anyway (A_B = 1).
Eq. 1.4 proves that the causal weight for Engineer A remains almost one:
while Engineer B's data point is scaled up by a factor of 20:
As Figure D shows, this re-weighting can evenly distribute population to the treatment and control group in the pseudo-population.
▫ Defining Selection Bias in Math
In the original historical logs, the conditional probability of seeing a specific profile X with a specific project assignment A_0 is governed by the standard product rule of probability:
Because human managers prefer certain backgrounds, the assignment probability P(X, A_0) changes drastically depending on X.
As we saw in the previous example,
For Engineer A, P(A_0 = 1 | X) = 0.95.
For Engineer B, P(A_0 = 1 | X) = 0.05.
Selection bias indicates that the confounder X and treatments A_0 are statistically dependent.
▫ Mitigating Selection Bias
Securing statistic independence between the confounder X and treatments A_0 can mitigate selection biases.
Let's look closely at how Eq 1.4 treats a person who actually received the treatment (A_i = 1).
For anyone in the treatment group, the second half of Eq 1.4 drops out because (1 - A_i) = 0.
Their individual weight simplifies to:
Now, let's observe what happens when we create a pseudo-population by multiplying our original observational probability distribution P(X, A_0=1) by this exact mathematical weight:
Substitute the definitions from Eq 2.1 and Eq 1.4 into this equation:
▫
By running the exact same math for the control group (A_0 = 0) and combine both branches back together, the new, synthetically weighted joint distribution of the dataset simplifies to:
Eq. 2.3 forces X and A_0 to become independent; the baseline features balance perfectly across both treatment branches.
This converts the heavily skewed observational logs into a clean synthetic sandbox.
Python Implementation: IPS in Action
Let’s implement this de-biasing pipeline in Python.
We will simulate a confounded corporate dataset where legacy managers over-indexed on an employee’s technical background (X) when assigning them to Tier-1 projects (T).
We will showcase how a standard model overestimates the impact of the project assignment, and how our IPS pipeline recovers the ground truth.
1import numpy as np
2import pandas as pd
3import sklearn.linear_model as lm
4import statsmodels.api as sm
5import statsmodels.formula.api as smf
6
7# simulate a dataset with a confounder (X), treatment assignment (A_0), and outcome (Y)
8np.random.seed(42)
9N = 12000
10
11X = np.random.normal(0, 1, N)
12
13prob_A = 1 / (1 + np.exp(- (1.8 * X)))
14A_0 = np.random.binomial(1, prob_A)
15
16
17true_beta_A0 = 0.6
18prob_Y = 1 / (1 + np.exp(- (-1.0 + true_beta_A0 * A_0 + 1.2 * X)))
19Y = np.random.binomial(1, prob_Y)
20
21df = pd.DataFrame({'X': X, 'A_0': A_0, 'Y': Y})
22
23# native estimation of the effect of A_0 on Y without any adjustment for confounding
24naive_model = smf.logit("Y ~ A_0", data=df).fit(disp=0)
25naive_beta = naive_model.params['A_0']
26
27# ips pipeline - estimating propensity scores using logistic regression
28propensity_model = lm.LogisticRegression(penalty=None)
29propensity_model.fit(df[['X']], df['A_0'])
30df['propensity_score'] = propensity_model.predict_proba(df[['X']])[:, 1]
31
32# check positivity violation: propensity scores should be bounded away from 0 and 1
33min_score, max_score = df['propensity_score'].min(), df['propensity_score'].max()
34print(f"Propensity Score Range: [{min_score:.4f}, {max_score:.4f}]")
35
36# compute ipw
37df['weight'] = df['A_0'] / df['propensity_score'] + (1 - df['A_0']) / (1 - df['propensity_score'])
38df['id'] = df.index
39
40# fit a GEE model to estimate the causal effect of A_0 on Y using the computed weights
41ips_model = smf.gee(
42 "Y ~ A_0",
43 groups="id",
44 data=df,
45 family=sm.families.Binomial(link=sm.families.links.Logit()),
46 weights=df['weight']
47).fit()
48ips_beta = ips_model.params['A_0']
49
50◼ Results
▫ Propensity Score Range: [0.0011, 0.9990]
The score range shows the lowest and highest probabilities the model calculated for a developer getting assigned to a Tier-1 project.
The range is incredibly extreme from almost zero to 1; a score of 0.0011 means a developer had a 0.11% chance of getting a Tier-1 project but got it anyway, while 0.9990 means they had a 99.9% chance.
This tells us that management's selection bias was extremely severe, creating a massive imbalance in who got selected for top projects.
▫ Intervention (treatment assignment) A_0
The ground truth: A_0 = 0.60
This indicates the actual, unconfounded impact of a Tier-1 project assignment to 1-year retention Y.
In a perfect world like a clean RCT experiment, giving a developer a Tier-1 project increases their baseline retention metrics by exactly 0.60.
This is the benchmark number the causal model is trying to find.
2. Naive observation by standard ML (logistic regression): A_0 = 1.6974
This is what a standard ML model sees if we just feed it raw historical data without correcting any biases.
The number is massively inflated (1.6947 vs the true 0.60).
Because managers historically gave Tier-1 projects to the highest-performing engineers, a standard model incorrectly credits the project for high retention, when in reality, those elite engineers were already highly likely to stay regardless of their assignment.
3. IPS re-weighted causal inference: A_0 = 0.4415
This is the calculation from the corrected causal inference pipeline after using IPS to strip away historical management bias.
It successfully broke the bias, moving drastically closer to the real-world truth of 0.60.
Note: It is slightly lower than 0.60 because of the extreme probability weights we saw in step 1, which introduce statistical noise, and because of how math behaves when dealing with log-odds binary outcomes.
IPS Bottleneck - Positivity Violations
While IPS is mathematically competitive, its real-world deployment faces a roadblock: the positivity violation.
Formally, the IPS math requires to secure non-zero probabilities
for every unique combination of baseline confounders X.
This indicates that all individuals in the original population must land in either the treatment or control group.
▫ Hitting the Wall: Strict Corporate Rules
But is it realistic?
Imagine our engineering organization in the use case enforces a rigid corporate rule:
Junior engineers with less than 12 months of tenure are strictly barred from participating in Tier-1 projects.
When the propensity model evaluates this junior subpopulation X_{junior}, the historical probability of treatment drops to absolute zero:
due to the new rule.
So, when the IPS pipeline attempts to calculate the counterfactual expectation for the treatment group, the denominator in the formula collapses:
making it impossible to run causal estimation.
As Eq. 3.3 shows, when a subpopulation has a probability of exactly 0 or 1, IPS fails completely.
In other words, no optimization and tuning efforts can recover a causal signal from an environment where alternative actions were never attempted.
One cannot simulate the strategy because we have zero historical data points to balance.
◼ How to Overcome the Positivity Violation in Production
When hitting a deterministic corporate policy, we'd deploy two primary mitigation strategies to save the pipeline:
▫ Option 1. Trimming and Restricting the Causal Manifold
The most pragmatic engineering solution is to redefine the scope of your causal inquiry.
If e(X_{junior}) = 0, we must explicitly remove junior engineers from the model's dataset entirely - and include only mid-level and senior engineers where true managerial discretion exists (0 < e(X) < 1).
This allows the model to regain mathematical stability, but we sacrifice scope.
"We can optimize routing for experienced engineers, but we cannot mathematically evaluate counterfactuals for junior engineers because alternative choices were never attempted."
▫ Option 2. Utilizing Dynamic Overlap via System Shocks (Natural Experiment)
If historical exceptions exist that break the rigid corporate rule, we can use them as counterfactual data whose e(X) > 0 is secured.
For example, a massive cloud outage occurred last quarter forced managers to temporarily pull junior engineers onto Tier-1 response teams.
This can be used to calculate valid weights for junior engineers.
Wrapping Up
By applying IPS, we successfully forced our historical log data to simulate an unbiased, randomized experiment.
We decouple an engineer's entry-level background from the true, isolated impact of their project placement.
But this brings us to the ultimate caveat of IPS: IPS is a static snapshot game.
◼ The Time Varying Trap
IPS assumes all baseline traits X are measured at day one, and the intervention A_0 is a single, permanent choice.
But in reality, corporate environments are continuous, evolving timelines.
Consider this common production feedback loop:
A junior engineer is hired.
At Month 3, they perform exceptionally well on a small task (time-varying confounder).
Because of this success, the manager overrides standard policy and promotes them early to a Tier-1 team (time-varying treatment).
Their performance at Month 6 dictates their final 1-year retention Y = 1.
When past treatments affect future confounders, standard static IPS is completely blindfolded.
To solve this challenge, I'll explore Time-Varying Confounding and the Descent into G-Estimation in Part 3.
◼ Causal Machine Learning Series
Part 1. Why Machine Learning Demands Causal Inference - Rethinking the Predictive Paradigm
Part 2. De-Biasing Historical Data Logs (without Expensive A/B Tests)
Why Machine Learning Demands Causal Inference
[Series] Causal Machine Learning - 1. Rethinking the Predictive Paradigm
Standard machine learning models excel at empirical risk minimization on static observational data, but fail catastrophically when an operational policy actively alters the data-generating distribution.
This advanced guide exposes the feature flattening trap—where models mistake downstream symptoms for upstream causes—and details how to deploy structurally invariant causal models using Judea Pearls Backdoor Criterion and Off-Policy Evaluation (OPE).
Causal inference is the formal statistical and mathematical framework dedicated to uncovering, quantifying, and predicting the independent, directional effects of specific variables (treatments) on targeted outcomes.
The below diagram illustrates how causal inference works, compared to standard, predictive machine learning:

Figure 1. Symmetrical Statistical Associations in Predictive ML vs. Directional Causal Inference Mechanics
Rather than treating data as a collection of symmetrical statistical associations (Left, Figure 1), causal inference models the underlying physical mechanisms and data-generating processes of the system (Right, Figure 1).
◼ Structural Causal Model (SCM) Components
To differentiate standard ML (correlation) from causal inference, we define a chronologically ordered directed acyclic graph (DAG) across four variables:
Baseline Confounder X
Intervention A_0 ∈ {0, 1}
Mediator M ∈ {0, 1}
Outcome Y ∈ {0, 1}
To anchor these concepts, we map each variable to a real-world hiring scenario.
▫ 1. Baseline Confounder X
Baseline confounder (confounder) refers to the pre-existing context or characteristics before any action is taken:
where:
f_X is a deterministic, non-parametric structural mapping function.
ε_X is mutually independent, unobserved background noise terms (exogenous variables) drawn from an arbitrary joint probability space.
Hiring context: The jobseeker’s background (e.g., years of experience, tech stack proficiency).
Causal mechanic: Acts as a confounder by simultaneously biasing the assignment choice (X → A_0) and inherently increasing candidate market mobility(X → Y), making them more likely to churn regardless of the intervention.
▫ 2. Intervention A_0 ∈ {0, 1}
The intervention refers to the initial action taken by human or other events:
Where:
f_A is a deterministic, non-parametric structural mapping function.
ε_A is mutually independent, unobserved background noise terms (exogenous variables) drawn from an arbitrary joint probability space.
Hiring context: The hiring manager's decision to hire (1) or reject (0).
Causal Mechanic: The decision is driven by the confounder X (the jobseeker's background) and unobserved management heuristics ε_A such as the vibe check, impromptu deep-dive, and even mood and fatigue.
For example, the manager might think, "They have the technical skills, but their communication felt a bit hesitant during the system design round."
That hesitation isn't a standardized metric; it's a subjective interpretation (ε_A).
Or, if the manager is interviewing the candidate at 4:30 PM on a Friday after a brutal production outage, their decision threshold might be entirely different than it would be at 10:00 AM on a Tuesday.
▫ 3. Mediator M ∈ {0, 1}
The meditator refers to an incident happened after the intervention:
Where:
f_M is a deterministic, non-parametric structural mapping function.
ε_M is mutually independent, unobserved background noise terms (exogenous variables) drawn from an arbitrary joint probability space.
Hiring context: The specific project assignment given to the employee after they join the company.
Causal mechanic: The intervention (the hiring decision) triggers a behavioral shift (A_0 → M), capturing the indirect effect of the treatment.
▫ 4. Outcome Y ∈ {0, 1}
The outcome is the consequence we'd observe after the intervention and mediator:
Where:
f_Y is a deterministic, non-parametric structural mapping function.
ε_Y is mutually independent, unobserved background noise terms (exogenous variables) drawn from an arbitrary joint probability space.
Hiring context: Promotion within the first year.
Causal mechanic: The terminal node endogenous to the system, structurally determined by the direct effects of the baseline context, the intervention, and the mediator.
The Limitation of Standard Machine Learning
The below diagram illustrate standard ML approach (top) and three causal inference approaches (bottom):

Figure 2. Structural comparison displaying a standard flattened machine learning input layer versus causal directed acyclic graph frameworks. (Created by Kuriko IWAI)
◼ Statistical View of Standard ML
As shown in Figure 2, standard ML treats confounders X, intervention A_0, and mediator M equally as a flat layer of independent input features.
These features all point directly to the outcome Y, even when the true casual reality (left, Figure 2) has an open backdoor path between the intervention A_0 and the outcome Y.
This makes the optimizer shift weight to whatever features yield the highest immediate impact to the outcome, instead of isolating the true impact of the intervention.
Mathematically, standard ML throws observed features into the conditioning set of the conditional probabilities such that:
Where:
Y, A_0, M, and X is the outcome, intervention, mediator, confounder, respectively.
P(Y | ...) denotes the conditional probability distribution of the outcome Y given the conditioning set: A_0, M, and X.
And because the mediator M occurs in close temporal proximity to the outcome (Y = 1, indicating the contract termination), the observational data exhibits a strong conditional dependency such that:
Where:
Y = 1 indicates the final outcome, the contract termination.
M = Drop is the mediator, indicating a severe decline in communication response rate.
≈ 1.0 indicates the empirical conditional probability approaching unity due to tight chronological and statistical correlation between M and Y.
Consequently, the optimizer assigns maximum weight to the mediator M, concluding that "Communication degradation is the primary driver of turnover".
The challenge here is that an operational policy would misallocate capital toward the symptom (communication degradation) rather than the root cause.
For instance, leadership might decide to automate HR alerts to improve response rates, while leaving the true mechanism, the project mismatch entirely unaddressed.
◼ The Feature Flattening Trap
This fundamental failure of a standard ML in decision-making contexts stems from the feature flattening trap.
Eq. 1.1 denotes that the model completely ignores the structural dependencies and directional relationships between features by flattening them.
This induces two primary structural failures in production:
Mediator conditioning, and
Weight stealing.
▫ Challenge 1. Mediator Conditioning - Confusing Symptoms with Causes
By flattening the feature space, the model optimizes solely for predictive accuracy on the observational manifold.
It cannot distinguish between an upstream cause, the intervention A_0 and a downstream symptom, the mediator M.
Because M shares a high mutual information metric with Y due to its temporal proximity, the model treats the symptom as the lever.
▫ Challenge 2. Weight Stealing - The Statistical Masking
During back propagation, the optimizer attempts to identify the path of least resistance.
Because the mediator M sits closer to Y on the causal path, it absorbs the gradient updates during training.
Concurrently, because the model cannot map the directional flow X → A_0, the baseline confounder X leaks spurious correlation.
And the resulting parameters β's show a catastrophic distortion such that:
Where:
β_{M} is the estimated coefficient assigned by the model to the mediator M (communication drop).
β_{X} is the estimated coefficient assigned by the model to the confounder X.
β_{A_0} is the estimated coefficient assigned by the model to the primary action lever A_0 (project assignment).
Eq. 1.3. shows that the true cause - intervention A_0 - is masked entirely by a downstream symptom, the meditator M and an upstream context, the confounder X.
The Fallacy of Feature Importance (SHAP / Gain)
Post-hoc explainability methods like SHAP (SHapley Additive exPlanations) or tree-based feature importance do not reflect causal mechanisms.
For example, SHAP measures the marginal contribution of a feature to the model's mathematical output relative to the expectation over the current training distribution.
It does not map the physical topology of the real world.
A high SHAP value guarantees statistical predictive utility under the status quo policy, but provides zero guarantee of structural invariance under policy intervention.
Causal Inference Frameworks
Causal inference transitions the paradigm from passive observational conditioning to active, counterfactual intervention.
Unlike standard ML, the causal inference approach maps out the exact structural mechanics of how variables interact using Directed Acyclic Graphs (DAGs).
In this section, I'll explore three frameworks as shown in Figure 2:
Standard DAG.
Controlled Direct Effect (CDE).
Total Causal Effect (TCE).
Shipping AI Systems?
I help teams design and deploy scalable ML / RAG / LLM pipelines and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground
Standard DAG
Standard DAG establishes the foundational network of cause and effect where confounders X influence both the intervention A_0 and the mediator M.
The framework can acknowledge the baseline confounder X such as the human manager's bias affect who gets the treatment, and that the treatment flows through a downstream mediator M before hitting the outcome Y.
Mathematically, standard DAG is denoted as observational joint distribution factorization:
Where:
P(X, A_0, M, Y): The joint observational probability density function over all variables in the system.
P(X): The marginal distribution of the baseline confounder X such as a candidate's background context.
P(A_0 | X): Human bias. The conditional probability representing historical human policy. This models how heavily a manager's assignment action A_0 is influenced by the candidate's background context X.
P(M | A_0): The conditional probability tracking the downstream transition from action to mediator (e.g., the likelihood of a communication drop given a specific project match style).
P(Y | A_0, M, X): The conditional probability mapping the final outcome based on all preceding factors combined.
Eq. 2.1 represents the joint probability before any intervention, reflecting the historical data-generating process including human biases exactly as it exists in the data logs.
◼ Pros and Cons - Use Cases
Can serve as the structural hypothesis, before mapping out any domain knowledge.
Purely describes the status quo historical system. No mechanism to predict what happens if the network is disrupted by changing corporate policies.
Controlled Direct Effect (CDE)
Controlled Direct Effect (CDE) tackles this limitation of standard DAGs by isolating the direct impact of the intervention on the outcome by stripping away any influence from the mediator.
Mathematically, the Controlled Direct Effect (CDE) is defined as:
Where:
CDE(m) is the Controlled Direct Effect evaluated at a fixed mediator state m.
E[Y | ...] is the mathematical expectation operator under the designated interventional distributions.
do(A_0 = 1) and do(A_0 = 0) represent Judea Pearl’s interventional operators which set the treatment to active and baseline control states respectively.
do(M = m) denotes forcing the mediator to a static value m via a joint, secondary intervention.
Eq. 2.2 performs graph surgery on standard DAGs where the mediator M is held as a constant m using do-operator do(M=m).
▫ The Career Progress Scenario
In our tech pipeline, we want to isolate the Controlled Direct Effect (CDE) of the initial hiring decision (A_0) on a first-year promotion (Y), independent of the subsequent project assignment (M).
Imagine leadership wants to know: Does the raw signaling value of a high-bar hiring decision (A_0) inherently accelerate an employee's promotion velocity (Y), even if they are assigned to a low-visibility, maintenance-heavy project (M)?
To measure this via CDE, we enforce two simultaneous interventions:
Change the assignment policy: do(A_0 = 1) vs. do(A_0 = 0)
Hold M as constant m by invoking do(M = no_drop).
The second intervention can be a situation (m) where the company introduces a strict corporate policy that every new hire is uniformly assigned to the exact same baseline project, regardless of their background (X) or how highly they were rated during the hiring loop (A_0).
By mathematically locking M in place via do(M = m), we effectively sever the causal link from the hiring decision through the project assignment (from A_0 → M → Y to A_0 → Y).
◼ Pros and Cons
Best to assess if certain action has an independent path to the outcome.
Forces an artificial environment where the human behavior which acts as the mediator M is frozen while the policy A_0 is shifting, which is unrealistic in most real-world cases.
▫
Shipping AI Systems?
I help teams design and deploy scalable ML / RAG / LLM pipelines and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground
Total Causal Effect (TCE)
Total Causal Effect (TCE) can tackle the challenge of CDE by measuring the entire, unfiltered impact of the intervention on the final outcome Y.
In TCE, the mediator is allowed to flow naturally with the causal signal, instead of being blocked.
Mathematically, TCE can be denoted as the net change in outcome expectation generated across all downstream pathways:
Where:
E[Y | do(A_0 = 1)] is the expected value of the outcome Y in a counterfactual world where the entire population is actively forced to receive the intervention (A_0 = 1 or A_0 = 0)
do(A=a) represents Judea Pearl’s interventional operator.
For example, A_0 = 1 refers to the situation where every candidate is hired, whereas in A_0 = 0, every candidate is not hired.
This includes the meditator M block which directs to the outcome Y.
▫ Use Cases
Best for policy optimization and strategic ROI planning.
Can simulate the true, real-world impact of policy updates using historical data logs (No need to run an expensive A/B test).
▫ The Unconfoundedness Trap
Unconfoundedness trap is the situation where TCE assumes that all confounders are observed and adjusted.
This works against TCE especially when some unobserved feature influences both the policy and the outcome because TCE cannot capture this hidden feature in the first place.
For example, in the hiring / career progress example, a major hidden confounder could be an employee's hidden motivation or personal resilience level.
Highly motivated employees naturally seek out and volunteer for the most complex project because they want to prove themselves (hence, A_0 = 1).
Those candidates are inherently more likely to promote (hence, Y = 1) because of their strong work ethic and motivation.
This unobserved trait influences both the policy assignment and the outcome.
But here's the challenge.
Because the personal motivation metric isn't captured in the confounder, the causal model cannot adjust for it.
As a result, the TCE calculation falls into the unconfoundedness trap: it will absorb this hidden bias and incorrectly credit the low turnover rate entirely to the project assignment policy, creating a skewed ROI metric for leadership.
What Makes Causal Inference Differ From Standard ML
Causal inference isolates the interventional distribution such that:
Where:
Y is the random variable representing the terminal target outcome.
A_0 is the actionable treatment variable (e.g., project assignment policy).
a ∈ {0, 1} is the specific counterfactual assignment value enforced by the intervention.
do(A=a) is Judea Pearl’s interventional operator.
◼ Judea Pearl’s Do-operator
Judea Pearl’s do-operator (Judea Pearl, et. al, 2009) provides the mathematical syntax required to formalize this distinction by separating "seeing" (passive observation) from "doing" (active intervention).
Standard ML operates on the observational distribution denoted in Eq. 1.1, which conditions on the subpopulation that happened to receive treatment A = a under the historical, non-randomized policy.
The do-operator, denoted as do(A = a), represents a hypothetical, physical intervention that overrides the natural data-generating mechanism.
It forces the variable A to take the exact value a for the entire population, irrespective of historical tendencies.
For example, suppose we decide to programmatically overwrite a human manager.
We instantiate a strict routing policy that forces every single employee in the pipeline into a high-pressure project, completely ignoring their resume prestige, their historical background, or the managers' personal preferences.
Mathematically, we evaluate the interventional distribution:
Where do(A_0 = 1) represents the programmatic mutation of the system where we exogenously force the assignment A_0 to 1 for the entire incoming population (employees).
▫ The Enterprise Unlock: Off-Policy Evaluation (OPE)
Shifting from P(Y | A_0) to P(Y | do(A_0)) enables counterfactual Off-Policy Evaluation (OPE).
Instead of deploying an unverified algorithm to production and risking live revenue for instance, a causally identified model allows engineers to leverage biased historical logs to answer the counterfactual optimization problem:
What would our retention curve look like if we had executed policy A1 instead of the legacy human-driven policy A_old?
◼ Identification via the Backdoor Criterion
To recover the true interventional distribution from purely observational logs, we must locate an adjustment set Z that satisfies Pearl's Backdoor Criterion relative to the causal pair (A_0, Y).
Pearl’s Backdoor Criterion is the structural graph theory used to determine exactly which variables must be controlled for to isolate a true causal effect.
It provides the algorithmic rules to select a conditioning set of variables Z that blocks all spurious correlations without accidentally destroying or masking the true causal signal.
▫ The Two Rules of the Backdoor Criterion
A set of variables Z satisfies the backdoor criterion relative to an intervention A and an outcome Y that it passes two strict topological conditions:
Rule 1: No Downstream Mediators. No variable in Z can be a descendant of A. If a variable M is caused by A, meaning it sits downstream on the causal path like A → M → Y, M is a mediator or a symptom. If you control for it, you block the very effect you are trying to measure, which is what triggers the feature flattening trap.
Rule 2: Block All Upstream Leaks (The Backdoor Paths) Z must block every path between A and Y that contains an arrow pointing into A. An arrow pointing into A such as N → A → Y represents an upstream cause or a confounder (like human bias or background environment) impacting A. These paths allow statistical information to flow backwards from A, through the confounder, and into Y, creating an illusion of causality.
▫ The Backdoor Adjustment Formula
Once an adjustment set Z is mathematically validated via the Backdoor Criterion, we can safely rewrite the do-operator using standard, observable conditional probabilities:
By applying Eq. 4.1 to our specific staffing pipeline topology, M is structurally excluded, and X represents the support space of our baseline confounders—the continuous and discrete backdoor adjustments yield:
Where:
X is the complete support space of the baseline confounder X (e.g., the distribution of talent and prestige strata across the candidate pool).
P(Y | A_0 = a, X = x) is the standard conditional observational probability of the outcome given specific real-world realizations of the treatment action and background confounder.
P(X = x) or dP(X = x) is the marginal observational probability weight of each confounder stratum, used to re-weight the conditional estimates uniformly across the entire population.
▫ The Enterprise Unlock
Mathematically, Eq. 4.2.2 forces the historical data to simulate a counterfactual world where the assignment action A_0 was distributed completely at random across the background environment X (e.g., all candidates are assigned to complex projects).
This eliminates selection bias and enables engineers to execute a clean, synthetic A/B test directly out of old data logs, completely neutralizing the feature flattening trap.
Shipping AI Systems?
I help teams design and deploy scalable ML / RAG / LLM pipelines and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground
Production Implementation - Synthetic A/B Testing in Python
Let us simulate an enterprise dataset characterized by our structural causal topology.
After defining a confounded dataset, the script runs both standard ML and causal inference, and visualizes the profound estimation bias that occurs in production frameworks:
1import numpy as np
2import pandas as pd
3import statsmodels.api as sm
4import statsmodels.formula.api as smf
5
6
7## 1. define a confounded dataset
8np.random.seed(42)
9N = 10000
10
11# X: baseline context confounder (e.g., talent score)
12X = np.random.normal(0, 1, N)
13
14# A0: match action (historical human managers over-index on X when making matches)
15prob_A0 = 1 / (1 + np.exp(- (1.5 * X)))
16A0 = np.random.binomial(1, prob_A0)
17
18# M: downstream mediator (communication dropout - a bad match A0=1 causes communication dropouts)
19prob_M = 1 / (1 + np.exp(- (-2.0 + 2.5 * A0)))
20M = np.random.binomial(1, prob_M)
21
22# Y: true project exit - driven directly by the bad match AND the communication dropout. True total effect on Y is a combination of direct and mediated pathways
23prob_Y = 1 / (1 + np.exp(- (-3.0 + 1.2 * A0 + 1.8 * M + 0.5 * X)))
24Y = np.random.binomial(1, prob_Y)
25
26# create a dataframe
27df = pd.DataFrame({'X': X, 'A0': A0, 'M': M, 'Y': Y})
28
29
30# 2. standard ML approach (feature flattening)
31## throw the mediator M into the feature matrix.
32standard_model = smf.logit("Y ~ A0 + M + X", data=df).fit(disp=0)
33
34
35# 3. causal inference
36## structurally leave mediator M out of the regression
37causal_model = smf.logit("Y ~ A0 + X", data=df).fit(disp=0)
38
39
40# 4. visualize estimation bias
41models_data = {
42 'Model Type': [
43 'Standard ML (Flattened)',
44 'Causal Backdoor Adjustment'
45 ],
46 'Estimated Beta (A0)': [
47 standard_model.params['A0'],
48 causal_model.params['A0']
49 ],
50 'CI_lower': [
51 standard_model.conf_int().loc['A0', 0],
52 causal_model.conf_int().loc['A0', 0]
53 ],
54 'CI_upper': [
55 standard_model.conf_int().loc['A0', 1],
56 causal_model.conf_int().loc['A0', 1]
57 ]
58}
59
60results_df = pd.DataFrame(models_data)
61◼ The Simulation Results: Proof of the Trap
By running the Python script, we generate a dataset where the initial match decision (A_0) has both a direct impact on project success and an indirect impact by causing a downstream communication dropout (M).
When we run both a standard machine learning and causal inference, the resulting coefficients expose a massive blind spot.
▫ The Results - Empirical Breakdown of the Coefficients
Variables | Ground Truth | Standard ML (Flattened Matrix) | Causal Inference (Backdoor Adjustment) |
Intercept | -3.00 | -2.95 | -2.58 |
X (Confounder) | 0.50 | 0.52 | 0.44 |
A_0 (Human action) | 1.20 (Direct Effect) | 1.11 (Captures only the direct path) | 2.00 (Captures the Total Causal Effect) |
M (Symptom) | 1.80 | 1.81 | Structurally Omitted |
Table 1. Empirical Parameter Comparison: Structural Ground Truth vs. Observational Feature-Flattened Frameworks
The Model Illusion
The Standard ML model will report a highly deceptive feature importance profile.
It will convince humans that a drop in communication (M = 1.81) is nearly twice as critical to fix than the actual matching process (A_0 = 1.12).
The Downstream Value Drain
If leadership uses the standard model's outputs to plan investments, the company will pour capital into downstream band-aids such as automated Slack nudges or communication alerts.
These interventions will ultimately fail because they leave the true, high-leverage driver—the broken matching habit—completely unaddressed.
The Causal Unlock
By utilizing Pearl's Backdoor Criterion and blocking only the baseline confounder (X), the Causal model uncovers the true structural coefficient of 2.00.
This gives leadership an accurate, non-confounded ROI metric to justify rewriting the entire onboarding and assignment policy.
Wrapping Up
While the Backdoor Criterion provides the structural blueprint to escape the Feature Flattening Trap, implementing it on real-world enterprise architectures introduces an immediate engineering bottleneck.
In our Python simulation, I utilized a clean, low-dimensional confounder X.
But in production, the baseline confounder X is high-dimensional.
Attempting a naive, exact stratification on such an expansive space triggers the curse of dimensionality where the data splits into empty strata, and math collapses.
Worse yet, real-world historical data is plagued by selection bias and institutional behavioral cloning.
Because legacy human managers systematically over-indexed on specific shortcuts (like assigning all Ivy League graduates exclusively to premier accounts), there are vast regions of the feature space where alternative choices were never attempted.
To run a true offline evaluation, we must find a way to re-weight our dirty observational data to create a balanced, equitable foundation.
◼ Up Next — Part 2: De-Biasing Historic Logs
▫ Synthetic Randomization via Inverse Propensity Scoring (IPS)
In the next installment of this series, we will transition from pure structural graph theory to scalable algorithmic execution.
I will explore how to use Inverse Propensity Scoring (IPS) to isolate and neutralize day-one human selection shortcuts.
◼ References
Judea Pearl, Causal inference in statistics: An overview
Architecting Semantic Chunking Pipelines for High-Performance RAG
Master critical chunking strategies for RAG to enhance retrieval accuracy and context retention.
In Retrieval-Augmented Generation (RAG), your model’s output is strictly capped by the quality of the retrieved context.
This technical deep-dive explores the transition from arbitrary text slicing to semantic optimization. We evaluate the trade-offs between fixed-token splits and advanced hierarchical structures, providing Python implementation patterns to ensure your vector database delivers coherent, context-rich information for complex queries.
Chunking is the process of breaking down large bodies of text into smaller, manageable pieces (chunks) before they are converted into mathematical representations called embeddings.
The below diagram illustrate the data ingestion pipeline and how chunking plays a key role in the pipeline:

Figure A. Technical diagram of the RAG data ingestion pipeline illustrating the flow from raw data to chunking, embedding, and high-dimensional vector storage (Created by Kuriko IWAI)
The process begins with raw, unstructured data in various formats like text (PDFs, docs), images, audio, and video.
The chunking process happens after the retrieval (second box, Figure A) where the data is broken down into smaller pieces called chunks.
By splitting a long document into smaller paragraphs or segments, the system can later retrieve only the specific part that answers a user's question, rather than the entire file.
Then each chunk is passed through an embedding model (an AI algorithm) that converts the content into a vector embedding, a long list of numbers (coordinates) that represent the semantic meaning of the chunk.
Lastly, these embeddings are stored in a vector store (database).
The vector space in Figure A has three dimensions for demonstration purpose, but usually the space is high-dimensional.
These data points are stored close together when they are considered related.
For example, if we have a chunk about "Golden Retrievers" and another about "Labradors," they will be mathematically near each other in the database, allowing the LLM to find relevant information almost instantly.
◼ Why Chunking Matters
Chunking matters for the following reasons:
Relevance: Small chunks ensure that RAG can retrieve the exact piece from the large document.
Cost efficiency: Processing smaller, targeted snippets saves on tokens and computation time.
Context retention: Well-chunked data maintains enough surrounding information to enable the LLM to comprehend the context on why and how.
Overall, chunking helps the system to retrieve the most relevant context to the user query, while saving input tokens (and fit the context into the LLM's context window).
Comparative Analysis: 5 Industry-Standard Chunking Strategies
Selecting a chunking strategy is not a one-size-fits-all decision.
This section explores five major chunking strategies:
Fixed-size chunking.
Recursive character chunking.
Document-specific chunking.
Semantic chunking.
Parent–Child (Hierarchical) chunking.
To understand how these methods diverge in practice, we will apply each to a sample text regarding Solar Energy Infrastructure.
▫ Sample Text
I'll use the sample text to see how each chunking strategy splits the text:
1text = "Solar panels, or photovoltaic cells, convert sunlight into electricity. This process happens at the atomic level. Some materials exhibit a property known as the photoelectric effect. This causes them to absorb photons and release electrons. Beyond the cells, an inverter is required to convert DC to AC. Large-scale solar farms also require battery storage systems to manage peak load during non-sunny hours."
2◼ Fixed-Size Chunking
The fixed-size chunking is the most straightforward approach to define a specific number of characters or tokens per chunk.
The below diagram illustrates how it works:

Figure B. Visualization of fixed-size chunking showing the sliding window mechanism with defined chunk size and yellow-highlighted overlap section (Created by Kuriko IWAI)
For example, the chunk size (Green cells, Figure B) and chunk overlap (or called sliding windows) (yellow cells, Figure B) are set to 500 tokens / 50 tokens respectively.
The overlap ensures that context isn't lost if a key sentence is split in half.
▫ Pros
Computationally affordable and easy to implement.
▫ Best For
Quick prototyping.
Handling simple text.
General use cases where speed is prioritized over granular semantic accuracy.
▫ Practical Implementation
The CharacterTextSplitter class from the langchain_text_splitters library can split the sample text:
1from langchain_text_splitters import CharacterTextSplitter
2
3# fixed size chunking
4fixed_splitter = CharacterTextSplitter(
5 separator="",
6 chunk_size=100,
7 chunk_overlap=20
8)
9
10fixed_chunks = fixed_splitter.split_text(text)
11The configuration shows 100 tokens for each chunk with 20 tokens overlapped.
▫ Resulting Chunks:
Each chunk contains exactly 100 tokens:
Chunk 1: "Solar panels, or photovoltaic cells, convert sunlight into electricity. This process happens at the a"
Chunk 2: "ns at the atomic level. Some materials exhibit a property known as the photoelectric effect. This ca"
In this method, a word like "atomic" is sliced.
Although computationally fastest, the method can create semantic noise as the LLM receives partial words, which can degrade the quality of the generated response.
◼ Recursive Character Chunking
The recursive character text splitting uses a hierarchy of separators to find a natural breaking point, instead of cutting text at a hard character limit.
The below diagram illustrates how the method works:

Figure C. Diagram of recursive character splitting logic demonstrating the hierarchical priority of separators like newlines and periods to preserve sentence integrity (Created by Kuriko IWAI)
The method first attempts to split by the most significant separator, period, and then moves down the list for commas and spaces, until the chunk size requirement (pink box, Figure C) is met.
▫ Pros
Keeps related ideas together better than fixed-size splitting.
▫ Best For
Maintaining the integrity of paragraphs and sentences.
Articles and blogs.
▫ Practical Implementation
The RecursiveCharacterTextSplitter class from the langchain_text_splitters library can split the sample text:
1from langchain_text_splitters import RecursiveCharacterTextSplitter
2
3recursive_splitter = RecursiveCharacterTextSplitter(
4 chunk_size=100,
5 chunk_overlap=20,
6 separators=["\n\n", "\n", " ", ""]
7)
8
9recursive_chunks = recursive_splitter.split_text(text)
10The configuration shows 100 tokens for each chunk with 20 tokens overlapped.
The splitters have priority of double lines, single lines, double spaces, and single spaces.
▫ Resulting Chunks
Each chunk contains exactly 100 tokens such that:
Chunk 1: 'Solar panels, or photovoltaic cells, convert sunlight into electricity.'
Chunk 2: 'This process happens at the atomic level. Some materials exhibit a property'
Compared to the fixed-size chunking method, the recursive splitter identifies the period at the end of the first sentence and stops there, preserving grammatical integrity.
This makes the method more readable for the LLM.
◼ Document-Specific Chunking
The document-specific chunking respects the inherent format of the file types like Markdown, HTML, LaTeX, or Code.
For example:
Markdown: Splits by headers (#, ##, ###).
HTML: Splits by html tags, comma, or dots.
Code: Splits by function or class definitions.
▫ Pros
Preserves the logical hierarchy of the document.
▫ Best For
Highly structured technical documentation like PDF reports, manuals.
Codebases.
▫ Practical Implementation
The MarkdownHeaderTextSplitter class from the langchain_text_splitter library can define the splitters and split the document:
1from langchain_text_splitter import MarkdownHeaderTextSplitter
2
3markdown_document = """
4# Solar Energy Guide
5
6## The Physics
7Solar panels, or photovoltaic cells, convert sunlight into electricity.
8This process happens at the atomic level.
9Some materials exhibit the photoelectric effect.
10
11## The Hardware
12Beyond the cells, an inverter is required to convert DC to AC.
13Large-scale solar farms also require battery storage systems.
14
15### Maintenance
16Regular cleaning of panels ensures maximum photon absorption.
17"""
18
19# define the headers
20headers_to_split_on = [
21 ("#", "Header 1"),
22 ("##", "Header 2"),
23 ("###", "Header 3"),
24]
25
26# initialize the splitter
27markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
28
29# split
30md_header_splits = markdown_splitter.split_text(markdown_document)
31▫ Resulting Chunks:
Each chunk has been sliced by the headers defined in the code snippets:
Chunk 1.
Content: Solar panels, or photovoltaic cells, convert sunlight into electricity. This pro...
Metadata: {'Header 1': 'Solar Energy Guide', 'Header 2': 'The Physics'}
Chunk 2.
Content: Beyond the cells, an inverter is required to convert DC to AC. Large-scale solar...
Metadata: {'Header 1': 'Solar Energy Guide', 'Header 2': 'The Hardware'}
Chunk 3.
Content: Regular cleaning of panels ensures maximum photon absorption....
Metadata: {'Header 1': 'Solar Energy Guide', 'Header 2': 'The Hardware', 'Header 3': 'Maintenance'}
The method can leverage the author's intent, ensuring that "The Physics" and "The Hardware" are never accidentally blended into the same chunk, which is vital for technical manuals.
◼ Semantic Chunking
The semantic chunking is a more advanced technique that calculates the distance of the meaning to determine where a topic changes.
The method looks at the cosine similarity between the embeddings of consecutive sentences.
When the similarity drops below a certain threshold, it assumes a new topic has started and creates a break to move onto a new chunk.
▫ Pros
High retrieval accuracy because chunks represent complete ideas.
▫ Best For
Academic paper.
Narrative-heavy documents.
Long-form essays (paragraphs don't align with the topic shift).
▫ Practical Implementation
I'll first create vector embeddings using the SentenceTransformer class from the sentence_transformers library.
Then, split the embeddings into smaller chunks by calculating cosign similarity scores between embeddings.
1from sklearn.metrics.pairwise import cosine_similarity
2from sentence_transformers import SentenceTransformer
3
4# split the text into sentences
5sentences = split_into_sentences(text)
6
7# create vector embeddings
8model = SentenceTransformer(MODEL)
9embeddings = model.encode(sentences)
10
11# compute cosine similarity to split into chunks
12chunks = []
13current_chunk = [sentences[0]]
14for i in range(1, len(sentences)):
15 prev_emb = embeddings[i - 1].reshape(1, -1)
16 curr_emb = embeddings[i].reshape(1, -1)
17
18 similarity = cosine_similarity(prev_emb, curr_emb)[0][0]
19 print(f"Similarity between sentence {i-1} and {i}: {similarity:.3f}")
20
21 # if similarity drops → meaning shift → split
22 if similarity < similarity_threshold:
23 chunks.append(" ".join(current_chunk))
24 current_chunk = [sentences[i]]
25 else:
26 current_chunk.append(sentences[i])
27
28# add last chunk
29if current_chunk:
30 chunks.append(" ".join(current_chunk))
31
32return chunks
33▫ Resulting Chunks
In this method, the system notices a shift in meaning between "release electrons" and "Beyond the cells."
Chunk 1. Solar panels, or photovoltaic cells, convert sunlight into electricity.
Cosign similarity: 0.196
Chunk 2. This process happens at the atomic level.
Cosign similarity: 0.313
Chunk 3. Some materials exhibit a property known as the photoelectric effect.
Cosign similarity: 0.546
Chunk 4. This causes them to absorb photons and release electrons.
Cosign similarity: 0.266
Chunk 5. Beyond the cells, an inverter is required to convert DC to AC.
Cosign similarity: 0.336
Chunk 6. Large-scale solar farms also require battery storage systems to manage peak load during non-sunny hours.
Semantic chunking recognizes that the topic changed from physics to engineering and forces a split.
◼ Parent–Child (Hierarchical) Chunking
The parent-child (hierarchical) chunking involves storing two versions of the same data: a small child chunk for searching and a larger parent chunk for context.
The system first searches against small, highly specific chunks (e.g., 100 tokens).
Then, once a match is found, it retrieves the larger surrounding parent document (e.g., 1000 tokens) to provide to the LLM.
▫ Pros
Avoids the lost in the middle problem by giving the LLM plenty of background info.
▫ Best For
Enterprise-grade RAG systems.
Balancing high-precision search with comprehensive context.
▫ Practical Implementation
I'll first create parent chunk which contains all the sample text, and then create child chunks which contains vector embeddings:
1import re, uuid
2from sentence_transformers import SentenceTransformer
3
4# create parent chunk
5parent_chunk = {
6 "id": str(uuid.uuid4()),
7 "text": text.strip() # the entire sample text
8}
9
10
11# load embedding model
12model = SentenceTransformer("all-MiniLM-L6-v2")
13
14def create_child_chunks(parent_chunk):
15 sentences = split_into_sentences(parent_chunk["text"])
16
17 children = []
18 for sentence in sentences:
19 child = {
20 "id": str(uuid.uuid4()),
21 "parent_id": parent_chunk["id"],
22 "text": sentence,
23 "embedding": model.encode(sentence)
24 }
25 children.append(child)
26 return children
27
28child_chunks = create_child_chunks(parent_chunk)
29▫ Results
Parent context:
Solar panels, or photovoltaic cells, convert sunlight into electricity.
This process happens at the atomic level.
Some materials exhibit a property known as the photoelectric effect.
This causes them to absorb photons and release electrons.
Beyond the cells, an inverter is required to convert DC to AC.
Large-scale solar farms also require battery storage systems to manage peak load during non-sunny hours.
Matched child sentence:
Large-scale solar farms also require battery storage systems to manage peak load during non-sunny hours.
In the process, the retriever pulls the parent chunk when it finds that the query matches some vector embedding, instead of returning just the matched sentence.
This enables the LLM to receive the full paragraph and assess the relationship between solar panels, inverters, and battery storage. In other words, it explains the "Why" (infrastructure) rather than just the "What" (batteries).
Wrapping Up
Chunking is not just slicing data.
With a proper strategy, it can work as semantic optimization.
Proper grouping ensures that when a user asks a question, the vector database returns a coherent piece of information rather than a fragmented snippet that leaves the AI guessing.
Here are key strategies to consider when it comes to choosing the optimal chunking strategies.
◼ Implementation Roadmap: Choosing Optimal Strategy
▫ 1. Identify Patterns & Logical Structures
Look for repetitions, sequences, or inherent connections in the data.
In a technical context, this means identifying document headers, Markdown tags, or paragraph breaks to ensure a chunk doesn't cut off in the middle of a vital sentence or thought.
The key question:
Does my data have a predictable layout or specific syntax that carries meaning?
Strategy to choose: Document-specific (structure-aware) chunking.
Use parsers that respect the document's native format (e.g., Markdown, HTML, or LaTeX) to split data at logical boundaries rather than arbitrary character counts.
▫ 2. Maintain Semantic Context (The Mnemonic for AI)
Just as humans use mnemonics to link ideas, AI systems use overlapping chunks.
By including a small portion of the previous chunk at the start of the next one, you create a narrative bridge that prevents the model from losing the broader context of the data.
The key question to ask:
If I read this chunk in isolation, would I still understand the subject of the sentence?
Strategy to choose: Fixed-sized chunking with sliding window (overlapping).
Implementing a context window of 10–20% overlap between chunks ensures that the end of one chunk and the beginning of the next share enough connective tissue to maintain semantic flow.
▫ 3. Prioritize Categorical Grouping
Organize information by category or hierarchy (e.g., grouping a grocery list by "produce" or "dairy").
The key question to ask:
How granular is the information my users are looking for—specific facts or broad overviews?
Strategy to choose: Recursive Character Splitting.
Start with a large separator (like a double newline) and progressively move to smaller separators (space, character) until the desired chunk size is reached. This keeps neighboring ideas in the same bucket.
◼ Optimize for Retrieval & Relevance
Lastly, in either chunking strategy we choose, it is best to regularly test the chunk size against real-world queries because if chunks are too small, they lack context; if they are too large, they introduce noise that can confuse the LLM.
The key question one can ask is:
Am I retrieving irrelevant fluff that wastes my model's context window, or am I missing the answer entirely?
And if this is the case, experimental benchmarking would work the best.
The experimental benchmarking runs chunking with different chunk sizes (e.g., 256, 512, and 1024 tokens), and evaluates each of them using metrics like Hit Rate or MRR (Mean Reciprocal Rank).
It allows one to determine which size consistently yields the most accurate answers for a task in hand.
How to Build Reliable RAG: A Deep Dive into 7 Failure Points and Evaluation Frameworks
Master how to evaluate the RAG pipeline and solve common failures with DeepEval, RAGAS, TruLens, and Phoenix.
Building a RAG prototype is easy; ensuring it doesn't hallucinate in production is the real engineering challenge.
This article dissects the Seven Failure Points (FPs) of RAG—from missing content to incorrect specificity—and provides a technical roadmap for mitigation using industry-leading evaluation frameworks like DeepEval, RAGAS, and Arize Phoenix.
According to researchers Barnett et al., Retrieval Augmented Generation (RAG) systems encounter seven specific Failure Points (FPs) throughout the pipeline.
The below diagram illustrates these stages:

Figure A. Indexing and Query processes required for creating a RAG system. The indexing process is done at development time and queries at runtime. Failure points identified in this study are shown in red boxes (source)
Let us explore each FP arranged according to the pipeline sequence, following the top-left to bottom-right progression shown in Figure A.
◼ FP1. Missing Content
Missing content happens when the system is asked a question that cannot be answered because the relevant information is not present in the available vector store in the first place.
The failure occurs when an LLM provides a plausible-sounding but incorrect response instead of stating it doesn't know.
◼ FP2. Missed the Top-Ranked Documents
This is a situation where a correct document exists in the vector store, but the retriever fails to rank it highly enough to include it in top-k documents fed to an LLM as context.
In consequence, the correct information never reaches the LLM.
◼ FP3. Not in Context (Consolidation Strategy Limitations)
This is a situation where a correct document exists and is retrieved from the vector store, but is excluded during the consolidation process.
This happens when too many documents are returned and the system must filter them down to fit within an LLM's context window, token limits, or rate limits.
◼ FP4. Not Extracted
This is a situation where an LLM fails to identify the correct information in the context, even though the correct information was in the vector store, and successfully retrieved/consolidated.
This happens when the context is overly noisy or contains contradictory information that confuses the LLM.
◼ FP5. Wrong Format
This is a situation where storage, retrieval, consolidation, and LLM interpretation are successfully handled, but the LLM fails to follow specific formatting instructions provided in the prompt, such as a table, a bulleted list, or a JSON schema.
◼ FP6. Incorrect Specificity
An LLM's output is technically present, but either too general or too complex compared to the user's needs.
For example, an LLM generates simple answers to a user query with a complex professional goal.
◼ FP7. Incomplete Answers
This is a situation where an LLM generates an output not necessarily wrong, but missing key pieces of information that were available in the context.
For example, when a user asks a complex question like "What are the key points in documents A, B, and C?", the LLM only addresses one or two of the sources.
How FPs Compromise RAG Pipeline Performance
Each of these FPs impact performance of RAG pipelines:
◼ Data Integrity & Trust Failures
When missing or incorrect information is present, the system is no longer a reliable source of information. Primary FPs include:
FP1 (Missing Content): The answer is not in the doc in the first place.
FP4 (Not Extracted): The LLM decides to ignore the correct answer in the doc.
FP7 (Incomplete): The LLM gives half-truths, missing important pieces.
◼ Retrieval & Efficiency Bottlenecks
The RAG pipeline can be inefficient when it misses key information in the retrieval and consolidation stages. Primary FPs include:
FP2 (Missed Top Ranked): The embedding model fails to select top-k embeddings.
FP3 (Consolidation Strategy): The script to trim docs to fit the LLM limits drops the most important parts.
◼ User Experience & Formatting Errors
Although correct, an output with poor readability or in a wrong format can compromise user experience. Primary FPs include:
FP5 (Wrong Format): The LLM fails to follow the specific output format like JSON.
FP6 (Incorrect Specificity): The LLM generates a lengthy output for a simple yes/no question, or vise versa (too brief answer to a complicated question).
The Evaluation Stack: Frameworks to Mitigate FPs
Evaluation metrics are designed to systematically mitigate these FPs.
This section explores major evaluation metrics with practical use cases.
▫ Major RAG Evaluation Metrics:
DeepEval
RAGAS
TruLens
Arize Phoenix
Braintrust
◼ DeepEval - The Unit Test before Deployment
DeepEval calculates a weighted score based on the criteria.
An LLM-as-a-judge (e.g., GPT-4o) evaluates each criteria against an LLM's output:

DeepEval leverages G-eval, a chain-of-thought (CoT) framework which takes the multi-step approach to evaluate the output:
Define a criteria to measure (e.g., "coherence,""fluency," or "relevance").
Generate evaluation steps (using an evaluator LLM).
Follow the evaluation step and analyzes the input and the LLM's output.
Calculates an expected weighted sum of the score of each criteria.
Leveraging the approach, DeepEval measures the score:
where:
w_i: The weight of a specific parameter like tone or helpfulness.
C_i: A specific score for the criteria i against an output O.
f: The LLM's Likert-scale assessment:
Types | Response Options | ||||
|---|---|---|---|---|---|
Agreement | Strongly Agree | Agree | Neutral | Disagree | Strongly Disagree |
Likelihood | Very Likely | Likely | Neutral | Unlikely | Very Unlikely |
Quality | Excellent | Above Average | Average | Below Average | Poor |
Frequency | Very Often | Often | Sometimes | Rarely | Never |
Numeric | 5 | 4 | 3 | 2 | 1 |
Table 1. The Likert-Scale Framework for LLM-as-a-Judge Scoring.
▫ Common Scenario in Practice
Situation: A technical documentation assistant (bot) for a complex software product seems to be working every time the engineer team updates the codebase.
Problem: No quantitative proof if the bot can still answer the user query (You just "think" it's working...).
Solution: Integrate a PyTest function as CI/CD regression suite into Github Action where DeepEval runs G-Eval and others metrics over a test case:
1# pytest component
2import pytest
3from deepeval import assert_test
4from deepeval.test_case import LLMTestCase, LLMTestCaseParams
5from deepeval.metrics import AnswerRelevancyMetric, FaithfulnessMetric, GEval
6
7def test_bot_silent_regression():
8 # setup metrics with threshold
9 relevancy = AnswerRelevancyMetric(threshold=0.85)
10 faithfulness = FaithfulnessMetric(threshold=0.85)
11
12 # geval (llm judge)
13 geval_correctness = GEval(
14 name="Correctness",
15 criteria="Determine if the actual output is factually accurate based on the expected output.",
16 evaluation_params=[
17 LLMTestCaseParams.ACTUAL_OUTPUT,
18 LLMTestCaseParams.EXPECTED_OUTPUT
19],
20 threshold=0.85
21 )
22
23 # define a test case
24 test_case = LLMTestCase(
25 input="How do I rotate API keys in the dashboard?",
26 actual_output="To rotate keys, go to Settings > Security and click 'Regenerate'.",
27 retrieval_context=["The security tab allows users to regenerate API keys for safety."
28],
29 expected_output="Users can rotate API keys via the Security section in Settings."
30 )
31
32 # assert the test case against the metrics
33 assert_test(test_case,
34[relevancy, faithfulness, geval_correctness
35])
36Expected results: If any score of the metrics drops below the threshold (0.85), the PyTest raises AssertionError - immediately failing the CI build, preventing the silent regression from reaching production.
▫ Pros
A variety of metrics (50+) including specialized bias and toxicity checks are available.
Seamlessly integrates with existing CI/CD pipelines.
No reference needed. Assess an output based solely on the prompt and provided context.
▫ Cons
The quality of evaluation heavily depends on the judge LLM's capabilities.
Computationally expensive when the judge LLM is a high-end model.
Developer Note - The Test Case for DeepEval
A set of LLMTestCase objects defines the test case that DeepEval runs.
In practice, this test case should contain most important user queries and labeled outputs with the retrieved context.
These can be retrieved from a JSON or CSV file.
◼ RAGAS - The Needle in a Haystack Optimizer
Retrieval Augmented Generation Assessment (Ragas) aims to evaluate RAG without human-annotated dataset by generating synthetic test sets.
Then, it computes flagship metrics:

Figure B. The RAGAS evaluation triad diagram connecting Question, Context, and Answer through Precision, Recall, Faithfulness, and Relevancy metrics (Created by Kuriko IWAI)
The flagship metrics are categorized into the three groups:
Retrieval pipeline (black, solid line, Figure B): Context precision, context recall.
Generation pipeline (black, dotted line, Figure B): Faithfulness, answer relevancy.
Ground truth (red box, Figure B): Answer semantic similarity, answer correctness.
For example, faithfulness calculates the overlap between the claims in the response and the retrieved context such that:
where:
X_AC: The number of the claims in the answer (response) A supported by the given context, and
X_A: The total number of the claims in the response A (with or without the context supported).
▫ Common Scenario in Practice
Situation: The RAG system for legal contracts is missing key clauses. You are unsure if the problem is in the Search (Retriever) or the Reading (Generator).
Problem: No idea on the optimal top-k (number of chunks retrieved).
Solution: Use RAGAS to create a synthetic test set with 100 pairs of questions and evidence. Then, run the RAG pipeline against the test set to calculate context recall and context precision:
1from datasets import Dataset
2from langchain_openai import ChatOpenAI, OpenAIEmbeddings
3from langchain.docstore.document import Document
4from ragas import evaluate
5from ragas.testset.synthesizers.generate import TestsetGenerator
6from ragas.metrics.collections import context_precision, context_recall, faithfulness, answer_relevancy
7
8# setup models
9generator_llm = ChatOpenAI(model="gpt-3.5-turbo")
10critic_llm = ChatOpenAI(model="gpt-4o")
11embedding_model = OpenAIEmbeddings()
12
13# setup documents
14langchain_docs = [
15 Document(page_content=doc_1),
16 Document(page_content=doc_2),
17]
18
19# instantiate generator and generate synthetic testset w/ 100 pairs
20generator = TestsetGenerator.from_langchain(
21 llm=generator_llm,
22 embedding_model=embedding_model
23)
24testset = generator.generate_with_langchain_docs(langchain_docs, testset_size=100)
25test_df = testset.to_pandas()
26
27### <--- rag pipeline execution --->
28
29# create results dataset w/ the rag pipeline
30results_data = {
31 "question": test_df["question"
32 ].tolist(),
33 "contexts": [rag_pipeline.get_chunks(q) for q in test_df["question"
34 ]
35 ],
36 "answer": [rag_pipeline.get_answer(q) for q in test_df["question"
37 ]
38 ],
39 "ground_truth": test_df["ground_truth"
40 ].tolist()
41}
42result_dataset = Dataset.from_dict(results_data)
43
44# evaluate the results w/ metrics
45score = evaluate(
46 dataset=result_dataset,
47 metrics=[
48 context_precision,
49 context_recall,
50 faithfulness,
51 answer_relevancy
52],
53 llm=critic_llm,
54 embeddings=embedding_model,
55)
56Expected result: Depending on the metric results, action plan can be the following:
Metric | Score | Diagnostic | Action Plan |
Context Recall | Low | The retriever missed the correct info. | - Increase top-k. |
Context Precision | Low | Top-k chunks contain too much filter and noise - confusing the LLM. | - Decrease top-k |
Faithfulness | Low | The generator is hallucinating despite having data. | - Adjust system prompt. |
Table 2. RAGAS Diagnostic Action Plan - Mapping Scores to System Adjustments.
▫ Pros
Excellent for an early-stage project without ground-true datasets (As we saw in the code snippet, RAGAS can make a synthetic test set).
▫ Cons
Synthetic test set might miss nuanced factual errors.
Requires a robust extractor model to break down answers into individual claims (I used gpt-4o in the example).
◼ TruLens - The Feedback Loop Specialist
TruLens focuses on the internal mechanics of the RAG process rather than just the final output by using feedback functions.
For example, it measures answer relevance with a cosine similarity:
where Q and R represent the query and response respectively.
It also uses an LLM-based score reflecting how well the response satisfies the query's intent, using a 4-point Likert scale (0-3), making it superior for ranking the quality of different search results.
▫ Common Scenario in Practice
Situation: A medical advisor bot answers a user's question correctly but adds a pro-tip that isn't in the vetted PDF base.
Problem: The add-on pro-tip might be helpful, but not grounded.
Solution: Use TruLens to implement a groundedness feedback function with a threshold like score > 0.8:
1import os
2from trulens_eval import Tru, Feedback, Select, TruCustomApp
3from trulens_eval.feedback.provider.openai import OpenAI as tOpenAI
4
5# instantiate tru and evaluator model
6tru = Tru()
7provider = tOpenAI(model_engine=MODEL_NAME)
8
9# define the feedback func - compare the output vs source (chunks)
10f_groundedness = (
11 Feedback(
12 provider.groundedness_measure_with_cot_reasons,
13 name="Groundedness"
14 )
15 .on(Select.RecordCalls.func.args.context) # source (chunks)
16 .on_output() # output (llm response)
17)
18
19# wrap the rag pipeline w/ tru recorder
20tru_recorder = TruCustomApp(
21 rag_query_engine, # rag app
22 app_id="app_ver1",
23 feedbacks=[f_groundedness
24]
25)
26
27# execute the query w/ tru recoder
28with tru_recorder as recording:
29 res = rag_query_engine(
30 prompt="What are the side effects of Ibuprofen?"
31 )
32
33# retrieve the tru assessment results
34record_df, feedback_cols = tru.get_records_and_feedback(app_ids=['app_ver1'
35])
36Expected results: When the LLM generates a response that contains information not present in the retrieved chunks, TruLens flags the record in your dashboard.
▫ Pros
Visualizes the reasoning chain to identify exactly where the agent went off-track.
Provides built-in support for grounding to catch hallucinations in real-time.
▫ Cons
Learning curve for defining custom feedback functions.
The dashboard can feel heavyweight for simple scripts.
◼ Arize Phoenix - The Silent Failure Map
Arize Phoenix is an open-source observability and evaluation tool to evaluate LLM outputs, including complex RAG systems.
Built on OpenTelemetry by Arize AI, it focuses on observability by treating LLM evaluation as a subset of MLOps.
In the context of RAG evaluation, Phoenix excels at embedding analysis, using Uniform Manifold Approximation and Projection (UMAP) to reduce high-dimensional vector embeddings into 2D/3D space:
where n is the original dimension of the vector space, and d is the reduced dimension (e.g., d = 3)
This embedding analysis mathematically reveals if the failed queries are semantically grouped together, which indicates a gap in the vector database.
▫ Common Scenario in Practice
Situation: A customer support bot works great for refunds, but gives nonsensical answers to warranty claims.
Problem: Data hole in the vector database (Cannot find in logs).
Solution: Use Arize Phoenix to generate a Umap Embedding Visualization (UEV), a 3D map for the vector database - to overlay user queries on the document chunks.
Expected results: Visually see a cluster of user queries landing in the dark zone where no documents exist, telling that some documents are forgotten to upload to the vector store.
▫ Pros
OpenTelemetry-native; integrates with existing enterprise monitoring stacks.
The best tool for visualizing blind spots of the vector store.
▫ Cons
Less focused on scoring, more on observing.
Can be overkill for small-scale applications or single-agent tools.
◼ Braintrust - The Prompt Regression Safety Net
Braintrust is designed for high-frequency iteration cycles by using cross-model comparison.
It assesses if Model A + Prompt B is mathematically superior to Model C + Prompt D:
where R_A and R_B are the performance ratings of two different RAG configurations.
▫ Common Scenario in Practice
Situation: An engineer team upgrade prompt from "Answer the question" (Case A) to a more complex 500-word system instruction (Case B).
Problem: Improving the prompt for Case B might accidentally break Case A.
Solution: Use Braintrust to create a golden dataset with a set of N perfect examples (e.g., N = 50). Let Braintrust run side-by-side (SxS) comparison every time the team updates a single word in prompt:
1import braintrust
2from autoevals import Levenshtein
3
4# initialize the project
5project = braintrust.init(project="Prompt-Upgrade-Regression")
6
7# define the ground truth dataset (N=50)
8dataset = [
9 {"input": "What is 2+2?", "expected": "4"
10 }, # case a (simple)
11 {"input": "Explain quantum entanglement in the style of a pirate.", "expected": "Arr, particles be linked..."
12 }, # case b (complex)
13 ...
14]
15
16# evaluate
17braintrust.Eval(
18 name="Prompt Upgrade SxS",
19 data=dataset,
20 task=lambda input: {
21 "case_a": prompt_case_a(input), # current prompt
22 "case_b": prompt_case_b(input), # new, complex prompt
23},
24 scores=[Levenshtein
25],
26)
27Expected result: A difference report showing exactly which cases got better/worse for each of the golden dataset (N = 50).
▫ Pros
Extremely fast to test before the deployment.
Great UI for non-technical stakeholders to review and grade the output.
▫ Cons
Proprietary/SaaS-focused (though they have open-source components).
Fewer built-in deep-tech metrics compared to DeepEval or Ragas.
Shipping AI Systems?
I help teams design and deploy scalable ML / RAG / LLM pipelines and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground
Wrapping Up
When handled with proper evaluation frameworks, RAG can be a competitive tool to provide an LLM context most relevant to the user query.
◼ Implementation Strategy: Mapping Metrics to Failure Points
Although there’s no one-fit-all solution, Table 3 shows which evaluation metrics to apply for each FP we covered in this article:
Failure Point | Evaluation Metric Idea | Feature to Use |
FP1: Missing Content | RAGAS | Faithfulness / Answer Correctness |
FP2: Missed Ranking | TruLens | Context Recall / Precision |
FP3: Consolidation | Arize Phoenix | Retrieval Tracing & Latency Analysis |
FP4: Not Extracted | DeepEval | Faithfulness / Contextual Recall |
FP5: Wrong Format | DeepEval | G-Eval (Custom Rubric) |
FP6: Specificity | Braintrust | Manual Grading & Side-by-Side Eval |
FP7: Incomplete | RAGAS | Answer Relevancy |
Table 3. The Failure Point Mitigation Matrix - Which Tool Solves Which FP?
DeepEval and RAGAS can leverage their faithfulness metrics to measure data integrity failures (FP1, FP4, FP7).
TruLens leverages its context precision / recall to measure the context relevance to the output - effectively assessing FP2.
Arize Phoenix provides a visual trace of the retrieval process, making it easy to see if the document retrieved was lost during the consolidation (FP3).
For UX failures, DeepEval creates custom metrics to assess UX failures, while Braintrust excels at ground-truth dataset comparison.
Get 5-Point AI Security Checklist:
AI Engineering Masterclass
Module 3
Digital Clone: Persona Fine-Tuning & Edge Distillation
Engineered a high-fidelity interactive persona by distilling linguistic patterns from frontier models into a localized 3B parameter footprint.
unslothtrltransformersggufvllmsagemakerboto3openaiYou'll Build: Edge-Native Digital Clone (Smartphone/Web)

Production Goals:
Compress GPT 5.4 mini intelligence for edge AI.
What You'll Master:
- Distill latent reasoning and Chain-of-Thought (CoT) capabilities from GPT-5.4 into a 3B model.
- Engineer multi-stage tuning pipeline - SFT for grounding, RKD for logic, and DPO for stylistic parity.
- Standardize input/output schemas using chat templates.
- Implement 4-bit quantization (GGUF) to balance VRAM efficiency and perplexity for edge hardware.
- Deploy via AWS SageMaker LMI/vLLM engine for paged-attention concurrency and real-time streaming.
Agentic AI framework
versionhq is a Python framework for autonomous agent networks that handle complex task automation without human interaction.
Key Features
versionhq is a Python framework designed for automating complex, multi-step tasks using autonomous agent networks.
Users can either configure their agents and network manually or allow the system to automatically manage the process based on provided task goals.
Agent Network
When multiple agents handle a task, agents will adapt to specific network formation based on the task and network complexity.
You can specify a desired formation or allow the leader to determine it autonomously (default).
| Solo Agent | Supervising | Squad | Random | |
|---|---|---|---|---|
| Formation | 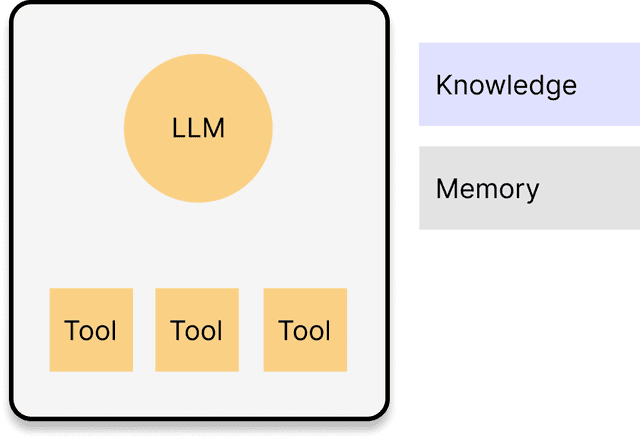 | 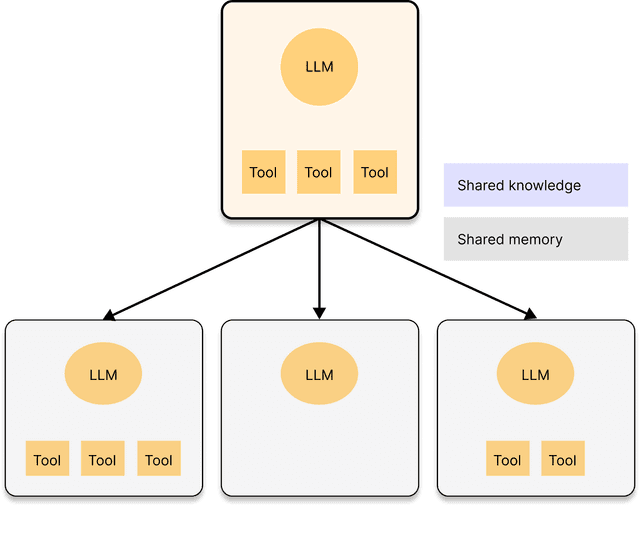 | 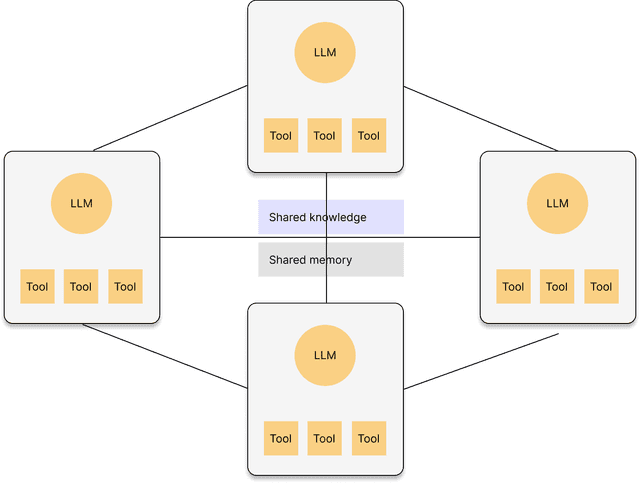 | 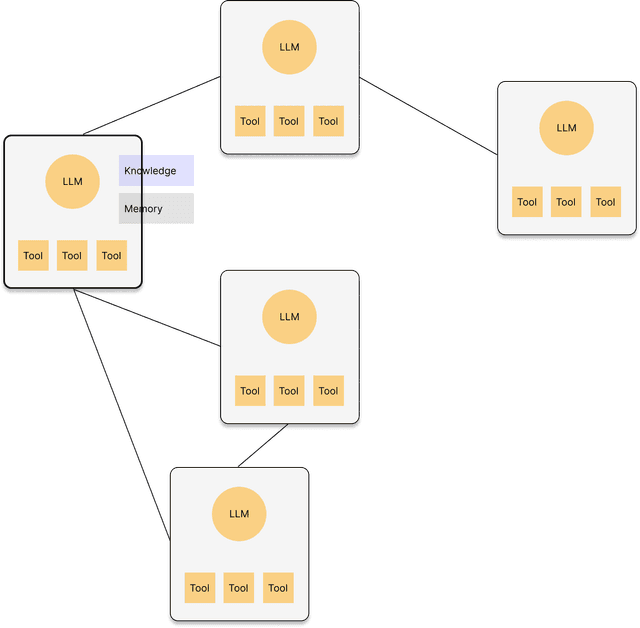 |
| Usage |
|
|
|
|
| Use case | An email agent drafts promo message for the given audience. | The leader agent strategizes an outbound campaign plan and assigns components such as media mix or message creation to subordinate agents. | An email agent and social media agent share the product knowledge and deploy multi-channel outbound campaign. | 1. An email agent drafts promo message for the given audience, asking insights on tones from other email agents which oversee other clusters. 2. An agent calls the external agent to deploy the campaign. |
Kuriko IWAI
Kernel Labs Pte. Ltd.
Kuriko IWAI
Shipping AI Systems?
I help teams design and deploy scalable ML / RAG / LLM pipelines and MLOps infrastructure.
Or explore:
- Dive deeper 👉 Research Archive
- Learn by building 👉 AI Engineering Masterclass
- Try it live 👉 Playground
Related Books
These books cover the wide range of ML theories and practices from fundamentals to PhD level.

Linear Algebra Done Right

Foundations of Machine Learning, second edition (Adaptive Computation and Machine Learning series)

Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems

Machine Learning Design Patterns: Solutions to Common Challenges in Data Preparation, Model Building, and MLOps